
Vehicle Detection
The last project of Term 1 of the Self-driving car engineer nanodegree by Udacity. Woohoo!!!
In this project, we learned about classifiers and feature extraction methods, and we had to build a pipeline that identifies cars on a video.
We had a collection of training data, which consisted of small images (64x64 pixels) of cars and not cars, around 8000 from each category. This sounds a bit weird but to successfully train a classifier, it has to be taught what a car is, and what a car is not. Here are some examples:
# Car images:







# Non-car images:







We used the HOG method (Wikipedia and a great article here) to extract features from the images. From a high level, this means that certain “useful” patterns are picked up by the feature extractor - patterns that define the object, that make it characteristic and identifiable. For instance, here are some extracted features of images representing vehichles:







These may not be very descriptive for the naked eye, but it seems to work for the classifier.
Based on the training data, we trained a linear classifier (Wikipedia) so that after it is fully trained, it is be able to put images into the correct category with at least 95% accuracy.
So now that we can classify tiny images, how do we use that for a video stream? The answer is something called the sliding window method. This means that in each frame, we are scanning through the image with predefined steps, and we classify the small frame that we are looking at. Another, faster method is to extract the features from the whole image, and then step through it with our small sliding window, so that the feature extraction is only done once, on the whole image, and the only task of the classifier is to decide whether those features on the current window correspond to a car or not.
There are of course various caveats in this process. We have to take into account that cars on the image can be large or small, close or far away. The solution to that is to use multiple window sizes on the area of the image where the cars are likely large (close to the camera). The sliding window method is demonstrated here - there are multiple box sizes from the small blue ones to the large white ones:
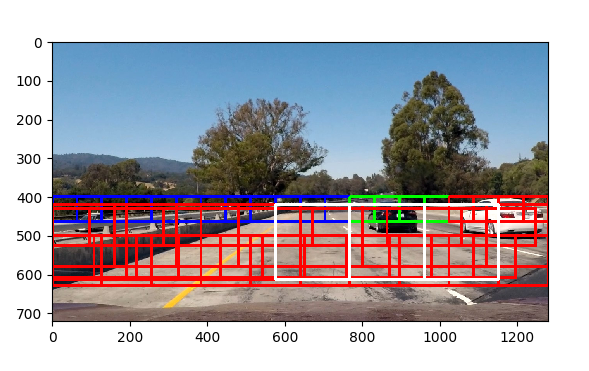
After sliding through the image above, the output of our classifier is the following:

We can see that there are multiple detections for the same car - this in itself is not a problem, because we can apply a so-called heatmap to the image, which identifies the hot areas where there are multiple detections:
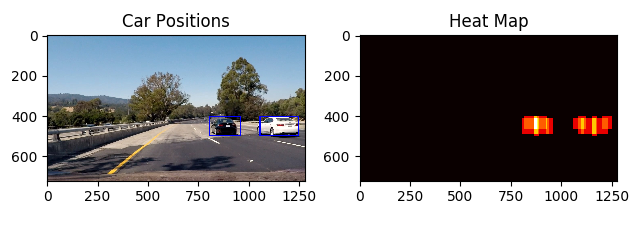
That heatmap looks good - we can fit bounding boxes to the hot regions and call it a good job. But if there are false positives in our detections, which appear on the heatmap, like this:
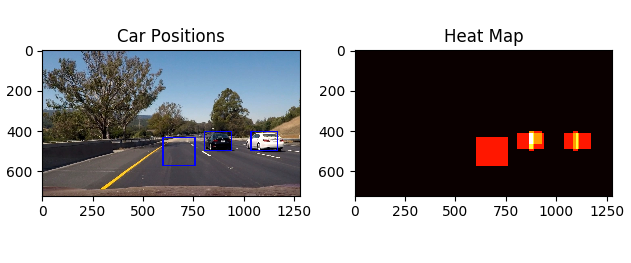
The answer is that we have to apply a threshold to the heatmap, so that areas which have only a few detections are ignored. Consider the following image:
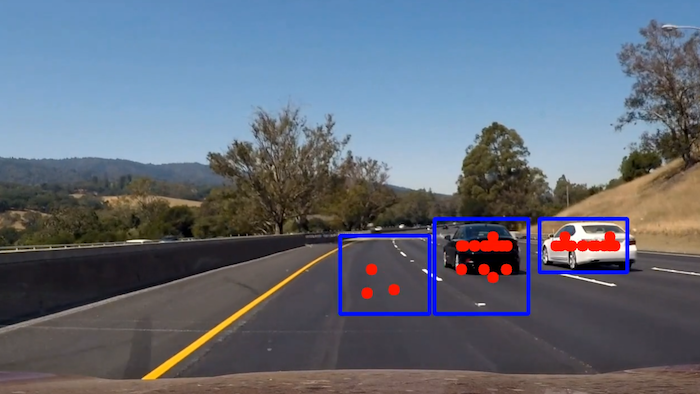
There is a false positive detection on the middle of the road. For some reason, that area was picked up three times by our classifier! However, we can see that the cars were indentified with much more certainty. So it seems we can define a threshold below which we would discard detections - in this case, this number is 3.
After some calibration and fine-tuning, we can then identify cars with a good confidence, and draw bounding boxes around them, like this:

Applying this method to every frame of the video stream gives OK results. But when we look at the video, we have one more advantage that we can exploit: we have information about previous frames. So if we use some caching, and give larger weights to areas where there was previously a car, we can build an even more robust vehicle-detection pipeline.

