
Speculative Decoding Research Overview
I’ve been digging into speculative decoding lately. It’s one of those ideas that feels obvious in hindsight: why run a huge model token by token when a smaller one can guess ahead and you just verify the guesses in parallel? The field has exploded since the foundational paper in 2023 (Leviathan et al.), and I wanted to map out what’s out there. Here’s a tour of the papers I reviewed, plus a summary of where things stand.
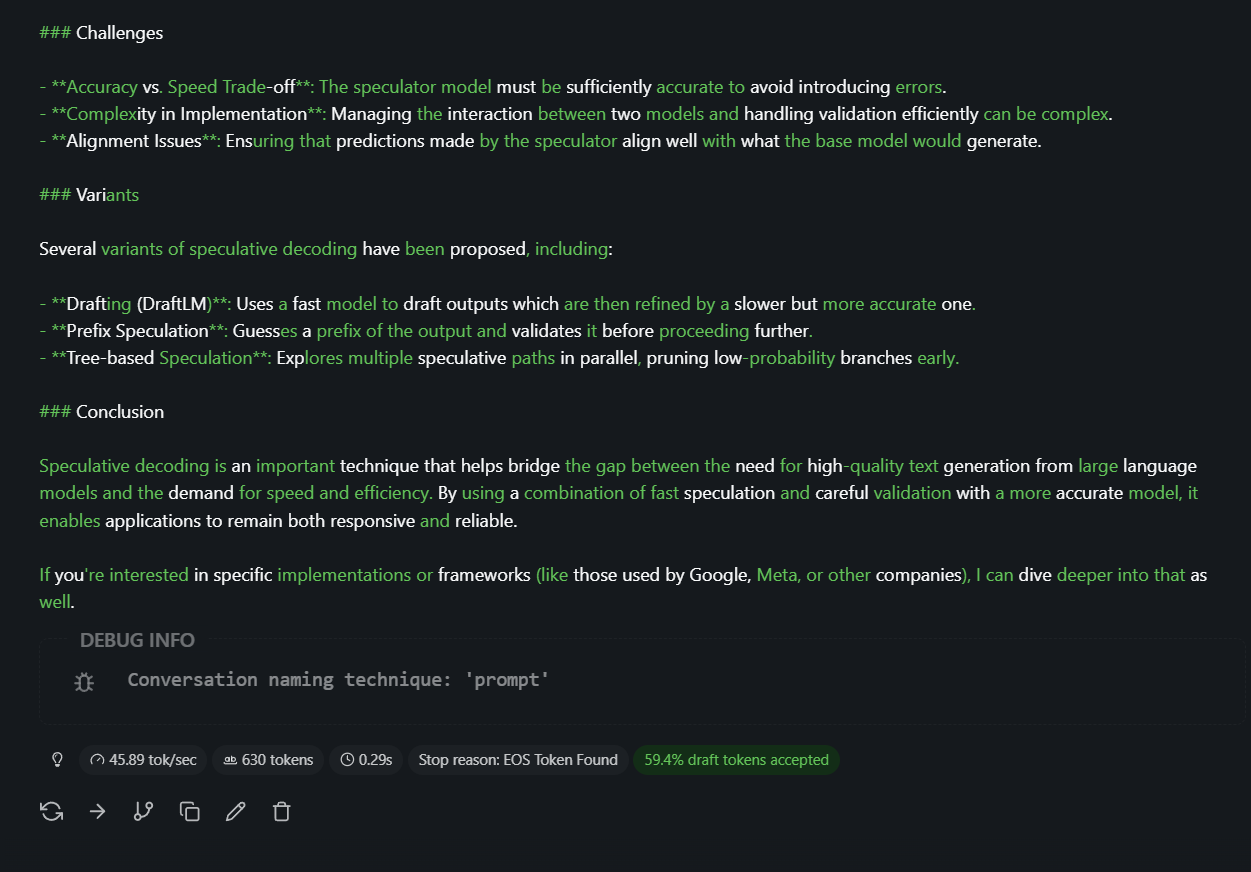
Screenshot from LM Studio running qwen3-14b as target model and qwen3-1.7b as draft
# The Core Idea
Autoregressive decoding is slow because each token depends on the previous one, so you can’t parallelize across time. Speculative decoding breaks that by having a cheap draft model propose several tokens at once. The target model then verifies them in a single forward pass. If the draft was right, you accept; if not, you correct and move on. The trick is doing this without changing the output distribution. The original Leviathan et al. paper showed you can get 2–3x speedup on T5-XXL with identical outputs.
What actually changes under the hood is not what the target computes, but how often it is invoked.
A common misconception is that the target model only evaluates the probabilities of the draft tokens. That is not the case. The target model still computes a full probability distribution over the entire vocabulary at every position, exactly like in standard decoding. The difference is that instead of doing this once per token, it does it once per block of tokens.
In other words, you are not reducing the cost of a forward pass. You are reducing the number of forward passes. Speculative decoding does not make the model cheaper per step. It makes each expensive step produce more tokens.
# Why is it guaranteed not to reduce capabilities?
The draft model never contributes to the final output. It only proposes candidates. Every token you emit either comes from the target model’s verification (when the draft was correct) or from the target model’s sampling (when the draft was wrong).
More precisely, the draft model is a proposal distribution , while the target model defines the true distribution . The algorithm combines accepted draft samples (when they align with ) and corrected samples drawn directly from . At the first mismatch, you don’t just take the draft’s guess. You sample the correction token from a residual distribution that conditions on the rejection. That residual is derived from the target model’s probabilities, so the next token is drawn from exactly the same distribution as if you had run the target by itself autoregressively. The draft is speculation; the target is the sole authority.
# Why is validation easier than generation?
Generation is inherently sequential. To get token 2 you need token 1. To get token 3 you need tokens 1 and 2. So generating K tokens means K forward passes, each blocking on the previous (this is why inference is so compute-heavy). You can’t parallelize across time.
Validation is different: you already have the K draft tokens. So you run the target model once on the full sequence (prompt + draft). In one forward pass, the transformer computes representations for every position and gives you the next-token distribution at each step.
The key technical reason this works is that transformers are parallel across sequence positions. With causal masking (basically, each position can look left at earlier tokens, but not right at future ones), the model can evaluate
in a single pass, as long as the prefix is known.
So instead of K forward passes → K tokens, you get 1 forward pass → up to K tokens. That is the entire speedup.
# Where does sampling actually happen?
In standard decoding, each step is:
where is the next token, is the target model’s probability distribution over the vocabulary, and is the context (all tokens before position ).
In speculative decoding, this is split into two phases:
-
Draft sampling. The draft model samples .
-
Target verification + correction. The target model computes the full distributions at each position, then accepts some draft tokens and rejects others, sampling replacements from a corrected version of .
So sampling still ultimately comes from , but it is partially delegated and then corrected.
# Why is the next-token distribution exactly the same?
This comes from acceptance-rejection sampling. The draft is the proposal; the target is the distribution we’re sampling from.
At each position, the draft proposes a token . The target accepts it with probability . If accepted, that token contributes exactly of the probability mass. If rejected, we sample from the remaining mass .
So the final probability becomes:
This is the key identity. The algorithm literally reconstructs by splitting it into two parts. So even though we use a different process, the marginal distribution of each emitted token is exactly identical to sampling directly from .
# What is actually expensive?
Each forward pass of a transformer includes full attention over the context, projection to the full vocabulary (logits), and softmax over all tokens. Speculative decoding does not reduce any of this. Instead, it amortizes it.
Normal decoding: 1 forward pass → 1 token. Speculative decoding: 1 forward pass → up to K tokens.
The draft model adds some extra work, but if , then:
# Model selection
Using a separate draft model adds system complexity (extra deployment and maintenance) and, when the draft and target distributions diverge, can hurt acceptance rates (Cha et al., KnapSpec). That motivates self-speculative methods, which avoid a second model (see later about self-speculative decoding).
# Why this works in practice
Two empirical facts make this viable:
-
Local predictability. Small models approximate large models well over short horizons.
-
Hardware utilization. GPUs are inefficient at single-token decoding. Longer sequences improve parallelism and throughput.
So speculative decoding improves both algorithmic efficiency (fewer passes) and hardware efficiency (better batching over sequence).
# See it in action
LM Studio visualizes the process in the chat: green text marks tokens the draft model proposed and the target model accepted; standard text marks draft proposals that the target rejected and replaced with its own sampling.
In the following screenshots and video, I’m using qwen3-14b as the target model, and qwen3-1.7B as the draft model. Important to note that the draft and target models have to be compatible, meaning they have to have the same tokenizer.
# Resources
# Foundational Work
Fast Inference from Transformers via Speculative Decoding (Leviathan et al., 2022) is the starting point. A small draft model proposes tokens; the target verifies in parallel. The key insight: hard LM tasks include easier subtasks that smaller models can approximate well. No retraining, no architecture changes. Just plug in a draft model and go.
SpecInfer (Miao et al., 2023) takes this further with tree-based speculation. Instead of a single draft sequence, you build a token tree of candidates. The LLM acts as a verifier over the whole tree in one pass, not as an incremental decoder. 1.5–3.5x speedup depending on setup. Open source in FlexFlow.
Draft and Verify (Zhang et al., 2023) removes the need for a separate draft model entirely. You use the same model: draft by skipping intermediate layers, verify with the full stack in one forward pass. Lossless, plug-and-play, no extra memory. Up to 1.99x on LLaMA-2.
# Verification and Drafting Variants
Block Verification (Sun et al., 2024) is a drop-in improvement. Instead of verifying token by token, you verify the whole draft block jointly. Theoretically optimal in expected tokens per iteration; never worse than token-level. 5–8% wall-clock gain. No added complexity. Good default for any speculative implementation.
LayerSkip (Elhoushi et al., 2024) from Meta: train with layer dropout (higher for later layers) and early-exit loss. At inference, early layers draft, remaining layers verify. Self-speculative with shared compute. 2.16x on summarization, 1.82x on coding. Code is open source.
EAGLE-2 (Li et al., 2024) uses context-aware dynamic draft trees. Draft confidence approximates acceptance rate. 3.05–4.26x speedup, 20–40% over EAGLE-1. Builds on the EAGLE framework. ICML 2024; widely adopted in practice.
SWIFT (Xia et al., 2024) is plug-and-play self-speculative: adaptively skips intermediate layers as draft, no auxiliary model, no training. 1.3–1.6x speedup. ICLR 2025. Good for quick deployment.
# Quantization
Speculative Decoding Meets Quantization (Zhang et al., 2025) shows that 4-bit quantization’s memory gains can be partly eaten by tree-style verification overhead. They propose a hierarchical framework: a small model turns tree drafts into sequence drafts, leveraging the quantized target’s memory access pattern. 2.78x on Llama-3-70B 4-bit, 1.31x over EAGLE-2. Directly relevant if you’re running quantized 7B or 30B on a single GPU.
# Recent (2026)
KnapSpec (Cha et al., 2026) formulates draft layer selection as a knapsack problem to maximize tokens per time. Decouples attention and MLP, models latency as a function of context length. Training-free, plug-and-play. Up to 1.47x on Qwen3 and Llama3.
# Summary Table
| Paper | Type | Speedup | Auxiliary Model | Training |
|---|---|---|---|---|
| Leviathan et al. | Dual-model | 2–3x | Yes | No |
| SpecInfer | Tree-based | 1.5–3.5x | Yes | No |
| Draft & Verify | Self-spec | 1.99x | No | No |
| Medusa | Heads | 2.2–3.6x | No (heads) | Yes |
| Lookahead | Exact parallel | 1.8–4x | No | No |
| Block Verification | Verification | +5–8% | No | No |
| LayerSkip | Self-spec | 1.82–2.16x | No | Yes |
| EAGLE-2 | Dynamic tree | 3–4.26x | Yes | Yes |
| SWIFT | Self-spec | 1.3–1.6x | No | No |
| SpecMQuant | Quantization | 2.78x | Yes | No |
| KnapSpec | Self-spec | 1.47x | No | No |
# Baseline for Reproduction
For reproducing on consumer hardware (e.g. RTX 5070 Ti, 16GB), Draft and Verify is the most practical baseline on paper: single model, no dual-model memory overhead, lossless, plug-and-play. You can layer Block Verification on top for another 5–8% gain. That said, it is not easily available locally. LM Studio and similar tools only support dual-model speculative decoding, not single-model draft-and-verify.
# Trying it locally
LM Studio (v0.3.10 release blog) supports speculative decoding, but only the dual-model variant: you must load a smaller draft model alongside your main model. It does not support single-model draft-and-verify (self-speculative). If you want to try dual-model speculation in LM Studio, pick a draft from the same family (e.g. Qwen 0.5B with Qwen 7B) so the tokenizer matches.
For single-model draft-and-verify, you need different tooling. The Draft and Verify paper has a reference implementation (Jupyter notebooks, PyTorch). LayerSkip (Meta) is another self-speculative option: use HuggingFace transformers with assistant_early_exit on LayerSkip-trained checkpoints like facebook/layerskip-llama2-7B. Draft and Verify works with standard checkpoints; LayerSkip requires models trained with their recipe.
# Wrapping Up
Speculative decoding has gone from a neat idea to a crowded field in a few years. The trend is clear: self-speculative methods (no auxiliary draft model) are winning for practical deployment, and verification improvements (block, multi-path) keep stacking. Quantization compatibility is still an open area, with SpecMQuant pointing the way.

