
The Dynamo paper
The Dynamo Paper is a widely influential document in the area of distributed systems, which summarises the techniques used by Amazon to be able to offer a highly available datastore at a massive scale. It’s a terrific read, balancing theory and practice perfectly.
⚠️ This is not about DynamoDB. Dynamo ≠ DynamoDB. Click for details.
Dynamo, unlike DynamoDB, is not an AWS offering for the public, as it was developed to be used only internally by Amazon. They are fundemantally different under the hood.
To name a few big differences, Dynamo has no GSI, no sort keys, it has leaderless replication (as opposed to DynamoDB which has single-leader replication), and it does not support strongly consistent reads.
The paper is influential not because it present groundbreaking new technologies but because of how it uses a combination of existing concepts to achieve a highly available DB at a large scale. I think it’s also a nice introduction to reading papers. It has been since elected into the SIGOPS Hall of Fame.
Here, I will summarise the key concepts for my own education, and this post is nothing more than a shortened re-phrasing of the paper. You might find reading the full paper more entertaining.
If you are more of a hands-on person, there is an extremely cool project which explores these concepts through implementation in Python - it’s called Pynamo. I have not yet given it a proper read, but already it looks like an awesome project.
📕 If you have read Designing Data Intensive Applications by Martin Kleppman, reading this paper will trigger feelings of déjà vu: many of the texbook examples of consistency, availability, partitioning, fault tolerance are put into practice here.
# Contents
# Historical context
# RDBMSs and access patterns
In the 2004 holiday shopping season, Amazon had a few outages, the root causes of which were traced back to “scaling commercial technologies beyond their boundaries”. 1 From the context and from other sources 2, this means that traditional SQL databases were struggling under the load that Amazon was subject to at peak times.
It also turned out that the usual database access patterns were largely that of a key/value store:
About 70 percent of operations were of the key-value kind, where only a primary key was used and a single row would be returned. About 20 percent would return a set of rows, but still operate on only a single table. 3
This is a sobering thought: transactions, table joins, strong consistency - core characteristics of relational databases - were not used.
# SLAs and percentiles
Amazon operates hundreds of services, and a single page load can result in accessing several dozens or even hundreds of underlying components, each serving a different purpose. To ensure that the website is functional and can deliver a good user experience, services define SLAs - the guarantees that define how fast it will give a result back to its caller.
SLAs are defined in percentiles: the average, median and expected variance are good metrics, but they do not give a full picture because they can hide outliers. To guarantee that all customers have a good experience, a percentile of 99.9 is used. The reason is that often times, the users with lots of data to process (large order history, lots if items in their cart, etc) are often the ones with the highest latency, and thus they are outliers. In addition, these customers are likely to be the most valuable ones (eg. placing lots of orders, or ordering items in bulk). Hence the chosen 99.9 percentile.
A related notion is tail latency: in the above example, the tail latency is the latency that those users experience who happen to fall into the worst 0.1 latency bucket.
# Techniques used
The following table nicely sums up the techniques used for each problem domain:
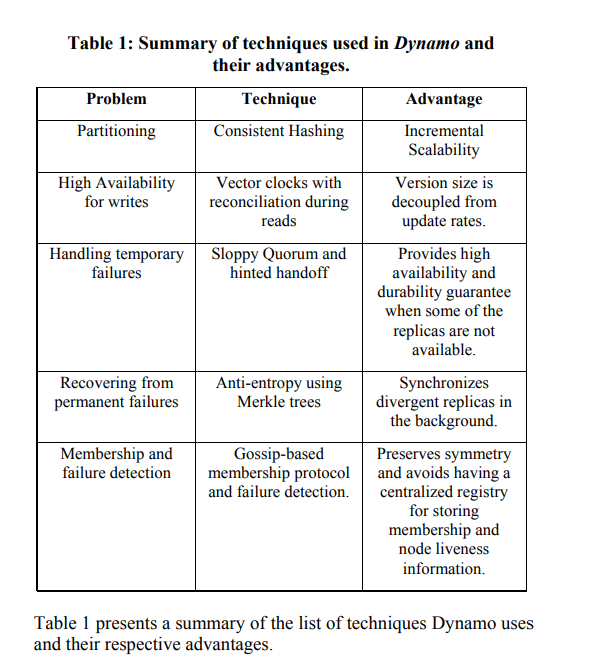
Let’s take a brief look at them one by one.
# Partitioning
Dynamo uses consistent hashing to distribute the data across multiple database nodes. This means that the output range of a hash function is treated as a fixed circular space or “ring”. Each node has a random place on this ring, and each node is responsible for storing the data whose hash value falls into the range between itself and the previous node on the ring. Thus, each node stores a range of hashes.
Due to replication, in addition to the node responsible for storing a value (the coordinator node), the item is replicated to N-1 other nodes on the ring (N being the replication factor). The coordinator is responsible for ensuring the replication of the item in addition to locally storing it.
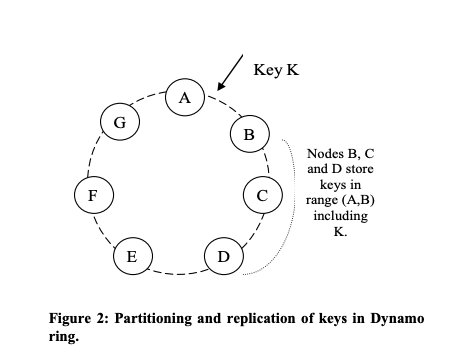
Consistent hashing is a big topic, but in short, its main advantage is that it minimises the amount of data that needs to be moved in case of the addition or removal of a node. A node failure, or the arrival of a new node (due to scaling out) only affects the data on the two neighbouring nodes - not all the data has to be redistributed.
Toptal has a comprehensive article about the ins and outs of consistent hashing here.
Consistent hashing comes with some disadvantages:
- randomly assigning nodes to the ring can result in non-uniform load distribution, and
- different nodes might have different performance characteristics (given that they might be using different hhardware).
To work around these, Dynamo uses virtual nodes: each node is assigned multiple points (tokens) on the ring. Each node might be responsible for multiple virtual nodes and thus differences in the underlying infrastructure can be accounted for by adding more tokens to the beefier machines, so the stronger server will be present on more points on the hash ring than a weaker server (the Toptal article from above gives a good summary for this).
# High Availability for Writes
Dynamo offers eventual consistency, where updates are propagated to all replicas asynchronously. When an update (put operation) is requested, Dynamo treats the result of each modification as a new, immutable version of the data, and it allows multiple versions to be present in the system at a time. In most cases, the system can reconcile the versions and decide which one is the most recent. In other cases, where version branching occurs, the system can end up with conflicting versions of an object. In these cases, the reconciliation logic is pushed to the client.
The paper cites the example of the shopping cart update: merging different versions of the shopping cart is done in a way which guarantees that an “add to cart” operation is never lost - but deleted items may re-appear.
# Quorum
As described above, Dynamo is based on a zero-hop distributed hash table, where each node has enough routing information to route any incoming request to the appropriate node directly. The list of nodes responsible for storing a particular key is called the preference list, and every node in the system knows about which nodes are on the preference list of a given key. Thus when a request comes in, a load balancer routes the request to a random node. If that node is not on the preference list for the target key, it forwards the request to the first node on the preference list. This node, which actually handles the operation, called the coordinator node, is responsible for the read or write operation.
The consistency model is based on a quorum, where N is the number of nodes, R is the minimum number of nodes that must participate in a successful read operation, W is the minimum number of nodes that must participate in a successful writ operation. R and W are configurable values, and setting them such that R + W > N results in a quorum-like system.
In case of a read (get) operation, it will request all existing version of data for that key from the top N reachable nodes from the preference list of the key, and waits for R responses before returning the results to clients.
# On vector clocks
In case of a write, the node will generate the vector clock for the new version of the value locally, and sends the new version and the vector clock to the first N available nodes on the preference list of the key. If at least W-1 nodes respond, the operation is successful.
“A vector clock is effectively a list of (node, counter) pairs. One vector clock is associated with every version of every object. One can determine whether two versions of an object are on parallel branches or have a causal ordering, by examine their vector clocks. If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. Otherwise, the two changes are considered to be in conflict and require reconciliation.” 4
In addition to locally storing each key within its range, the coordinator replicates these keys at the N-1 clockwise successor nodes in the ring. This results in a system where each node is responsible for the region of the ring between it and its Nth predecessor.
To account for node failures, preference list contains more than N nodes. Note that with the use of virtual nodes, it is possible that the first N successor positions for a particular key may be owned by less than N distinct physical nodes (i.e. a node may hold more than one of the first N positions). To address this, the preference list for a key is constructed by skipping positions in the ring to ensure that the list contains only distinct physical nodes.
Dynamo allows read and write operations to continue even during network partitions and resolves updated conflicts using different conflict resolution mechanisms.
# Handling temporary failures
Using techniques called “sloppy quorum” and “hinted handoff”, Dynamo can tolerate the case when, during a read or write of a value, some of the nodes on the preference list of a value are down. Martin Kleppman writes a great analogy:
[…] writes and reads still require w and r successful responses, but those may include nodes that are not among the designated n “home” nodes for a value. By analogy, if you lock yourself out of your house, you may knock on the neighbor’s door and ask whether you may stay on their couch temporarily. Once the network interruption is fixed, any writes that one node temporarily accepted on behalf of another node are sent to the appropriate “home” nodes. 5
Using this approach, Dynamo can handle temporary node failures and network errors. When the node is back up and running, the node temporarily hosting the data will eventually notice this and it will deliver the data to the now reachable, correct node.
# Recovering from permanent failures
To keep the replicas synchronized after failures, Dynamo uses Merkle trees. A Merkle tree is a tree data structure where each leaf node is the hash of a corresponding data item, and each parent node is the hash of the hashes of its children leaf nodes. This means that, while comparing the data stored on two different nodes, if the hash values of the root nodes of the two Merkle trees are equal, then the entire datasets are equal. If there is a difference between the root node hashes, then finding out exactly which data item is different can be done in log N time, where N is the number of leaf nodes.
In practice, this mean that each node maintains a Merkle tree per key range it hosts, and so nodes can compare the data of those key ranges by comparing the Merkle trees, and they can validate if they have the data matches. If they don’t match, they can perform the required data synchronization steps.
# Membership and failure detection
A gossip-based protocol makes sure that all nodes have a consistent view of the members of the ring. Every second, each node contacts another node, chosen at random, and they exchange their membership histories, and thus membership changes are eventually propagated across the entire cluster.
This also preserves the symmetry of the cluster, meaning that there are no special nodes - every node has the same set of responsibilities.
# Summary and resources
This was a fantastic, reader-friendly paper which made me read up about some concept in depth. I will try looking into Pynamo next and see all these techniques in action.
Some of the resources used (others are linked to inline):
-
See Sloppy Quorums and Hinted Handoff in Designing Data Intensive Applications ↩

