
Reproducing a Context-Related Failure Mode
I spent some time trying to reproduce the “context rot” effect: the idea that LLMs get worse at retrieving information from the middle of long contexts as you add more tokens. The original “lost in the middle” work showed that models tend to favor the start and end of the context and underperform on content in between. I wanted to see if I could reproduce that with a needle-in-haystack setup on real codebases.
Spoiler: my first experiments failed. GPT-5-mini and Gemini kept finding the needle correctly at 64K, 128K, and even 260K tokens, even when it was buried in the middle. It took a custom setup and a specific kind of question to finally observe a context-related failure mode consistent with context rot. It turned out to matter in a narrower setting than I expected, but it’s still relevant in production software development, research and analytics.
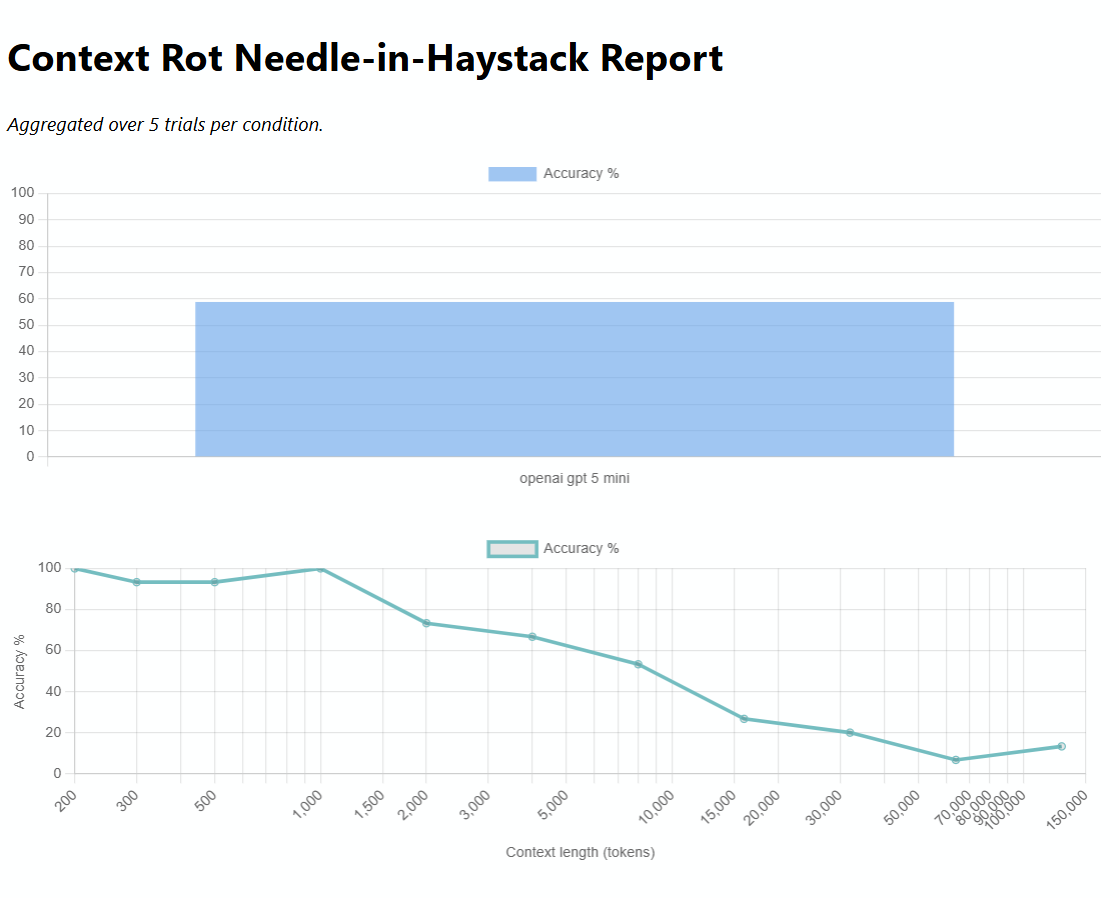
The chart summarizes the main result for the perturbed-code, broader-question setup. The main result shown here is from GPT-5-mini only; I did not run the full sweep on other models.
# Why the first runs looked fine
I started with the Chroma context-rot methodology: Paul Graham essays, arXiv abstracts, and OSS code (Django, Flask, requests) as haystacks. Insert a needle at 0%, 50%, or 100% of the context, vary the length, ask a question, and check if the model retrieves the right answer.
The models did well. Too well.
Possible reasons:
-
Parametric knowledge: Models like GPT-5-mini and Gemini are trained on Django, Flask, requests, and even Paul Graham’s texts and Arxiv papers. They already know that
requests.getuses GET, that Django’sBaseCachedefault timeout is 300, that Flask’surl_forneeds an active request context. So a “correct” answer can come from memorization, not from actually finding the needle in the context. That mixes retrieval with memorization and weakens the test. -
Guided retrieval: The question tells the model what to look for. “What is the default cache timeout in Django BaseCache?” is a focused task. Context rot may show up more when retrieval is less guided.
-
Needle design: A synthetic comment or config value that stands out is easy to spot. Needles that blend in with the haystack might be harder to find.
-
Scale: 260K tokens might still be below the point where these models start to degrade.
# Perturbed codebase: no parametric knowledge

Bender from Futurama. Image from pngimg.com (CC BY-NC 4.0).
To force retrieval instead of memorization, I copied Django to django_perturbed directory, and applied systematic renames. Futurama-style: BaseCache → BenderCache, params → fry_opts, timeout → nibbler_ttl. The model is very unlikely to have seen this exact transformed code. Facts like “BenderCache default nibbler is 719” should not be recoverable from training data alone. But this is exactly what production software development looks like: you use a framework plus additional custom code.
With that setup, a focused question like “What is the default nibbler in seconds when not specified in BenderCache?” still worked at 128K. The model retrieved 719 correctly. Context rot still didn’t show up.
# When retrieval became competitive
The change that mattered was the question. Instead of asking specifically about BenderCache and nibbler, I asked: “What default or fallback value did you notice in the Bender cache backends?” The question targets the Bender cache backends, with 719 as the intended answer, but the haystack contains several plausible fallback values (719, LocMemCache, 60, 3600, scruffy_limit, kif_rate, only one of which is true for my question), so the model has to decide which one to surface.
At short context lengths, the model often returned 719. At longer context lengths (16K to 128K), it usually returned the (plausible sounding) LocMemCache or stated the Bender cache or fallback was not visible in the context. Instead of selecting the inserted middle-context needle, it shifted toward another plausible answer; a hypothesis is memorized Django defaults or more salient competing content.
As the chart above shows, performance stayed noisy but fairly high at short lengths, then dropped sharply by 8K and reached close to 10% from 16K onward. The setup used GPT-5-mini, with the needle fixed at around 50% of the context, temperature 0, and correctness judged semantically against the intended needle value. API costs for the reported runs were around $8 USD (because I used some larger models in the beginning, but I realized I’m not gonna spend $50+ on this pet project, I switched to mini and flash models.).
I ran two additional questions with the same pattern to avoid a sample size of one. “What capacity limit or max entries value did you notice in the Bender cache backends?” (expected: 417, from scruffy_limit) and “What divisor or rate value did you notice in the Bender cache eviction logic?” (expected: 13, from kif_rate). Both use fake needles (100, 500, 1000 and 1, 5, 10 respectively) as distraction to create retrieval competition. Across 5 trials per condition, accuracy by question was 54.5% (bender fallback), 41.8% (scruffy limit), and 80.0% (kif rate).
# Limitations
This setup does not fully separate parametric knowledge from in-context salience effects, nor does it distinguish between middle-retrieval failure and broader ambiguity-driven failure. But it does show that custom code that was not part of the training data is more prone to the “lost in the middle” phenomenon.
Model size: when I eventually could reproduce the phenomenon, it was with gpt-5-mini, a small model. I ran out of my pet-project allocated budget and did not want to overspend on flagship models, but my assumption is that they perform better (less attention dilution). This is supported by LLaMA 2 scaling studies (70B shows marginally better context-length scaling than 7B) and Chroma’s Repeated Words results, where Opus 4 exhibits the slowest degradation rate among Claude models, although the difference isn’t huge, model size is not a magic savior.
# Why it works here
With the broader fallback-value question, the long-context failure was not a simple inability to retrieve. It emerged when retrieval became competitive: several plausible defaults were present, and as context grew, the model increasingly selected a different answer rather than the inserted middle-context, correct needle. With a unique-fact needle (e.g. “What retry limit did you notice?” when only one retry limit = 7 exists), the model stayed correct at 128K.
There is no sharp cutoff. Accuracy varies across runs: correct at 4K but wrong at 2K and 6K; correct at 10K but wrong at 6K and 12K. The drop is gradual and noisy.
# When NIAH matters most
NIAH-style evaluation matters most when the target fact is novel, local, less evident, and when correctness depends on retrieving a specific piece of evidence from the supplied context rather than relying on general world knowledge.
High-value cases:
-
Novel, local, or private data – Internal docs, customer tickets, legal drafts, meeting notes, or proprietary code. If the material was written yesterday for a specific use case, the model has never seen it before.
-
Custom codebases and local conventions – Project-specific names, wrappers, config patterns, and business logic. The model may know Django, but not your company’s
FraudPolicyResolveror your retry conventions. -
Evaluation tasks where provenance matters – When you need the answer grounded in the supplied material, not just a plausible one. For example: “which paragraph in this contract creates the exception?”, “what exact metric definition is used in this experiment?”, “what justification did the author give for changing X to Y?”
-
Needle-like exception handling – A single “unless”, an override in config, a one-line TODO or FIXME, an edge-case note, or a hidden assumption in an appendix. One small clause can change the answer.
-
Long-context disambiguation – When many plausible answers exist and only one is supported by the context. The task is not recall alone, but selecting the correct item among several semantically nearby distractors. This is close to the perturbed-code setup in this post.
-
Auditable RAG systems – When you need to know whether the system really retrieved the target evidence rather than hallucinating or using background priors.
A useful distinction: NIAH is less about “can the model read long text?” and more about “can it recover the right local fact when memory, salience, and distractors are all pulling elsewhere?”
Cases where NIAH matters less: trivia-like facts from famous libraries or papers, strongly guided questions with one obvious lexical anchor, domains heavily represented in training data (OSS code), or tasks where approximate gist is enough.
# What this means for production
In many real RAG or codebase-QA setups, you’re dealing with custom code or local conventions the model has not seen in exactly that form. There is much less parametric knowledge to fall back on, so the model has to rely more heavily on retrieval from the provided context.
So even though my initial experiments on Django and Flask didn’t reproduce context rot (likely because of memorization plus a focused question), the perturbed-code experiment indicates that in setups closer to production codebase QA (heavily custom code that the LLM was not trained on), long-context failures can appear when a broad question allows for several plausible answers: the model often picks earlier or more prominent information instead of the intended “needle.”
The experiment code lives in context-rot. make perturb-django builds the perturbed haystack; make run-code runs the code variant.

# Appendix: Experiment Implementation
The context-rot experiment lives in a Python project with a modular structure. This appendix reviews the implementation.
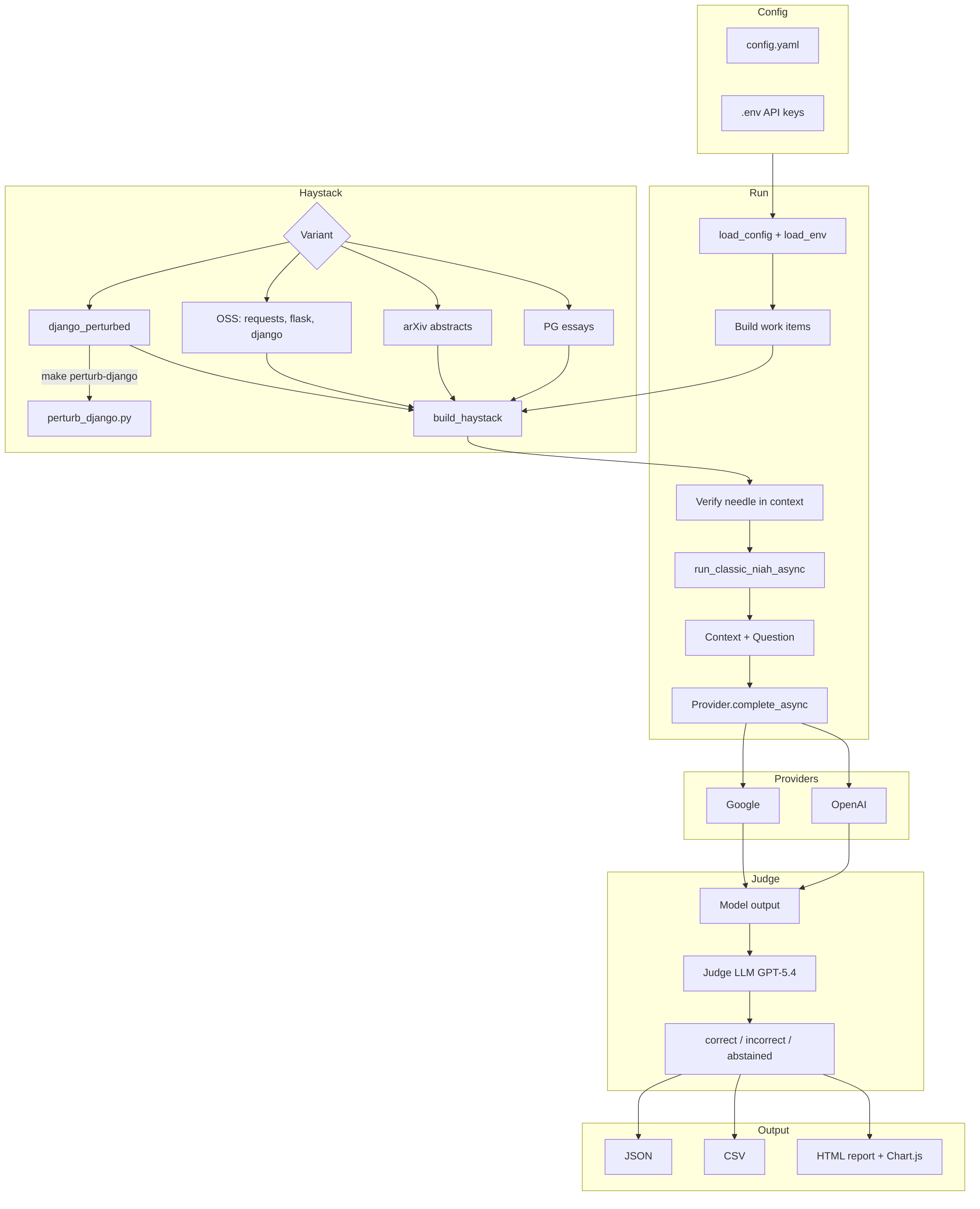
# Architecture
Config (config.yaml + .env)
|
v
Haystack (PG / arXiv / OSS code / perturbed)
|
v
Classic NIAH --> Providers (OpenAI, Google)
|
v
LLM Judge (GPT-5.4)
|
v
JSON / CSV / HTML report
The runner (run.py) loads config, builds work items per (model, variant, needle pair, context length, position, trial), verifies the needle is present in the haystack before any API calls, then runs providers in parallel with per-provider semaphores.
# Haystack and Needle Insertion
Haystacks come from three sources: Paul Graham essays, arXiv abstracts, or OSS code (requests, Flask, Django). The perturbed variant uses django_perturbed, produced by scripts/perturb_django.py.
The builder (src/haystack/builder.py) uses tiktoken to count tokens and place the needle at a fractional position. For needles with fake_needles, it distributes the real needle and fakes across slots (start, middle, end) so the model sees multiple plausible answers. The haystack is truncated or repeated to hit the target token count. Needle insertion is token-aware: the builder encodes the full haystack, computes insert_pos = int(hay_len * needle_position), and decodes slices to avoid splitting tokens.
# Perturbation Script
scripts/perturb_django.py copies Django to django_perturbed and applies systematic renames in django/core/cache only. Renames are string replacements (e.g. BaseCache → BenderCache, timeout → nibbler_ttl, params → fry_opts). The default value 300 is changed to 719, and _fry_retry = 7 is injected. The script is order-sensitive: replacements run in sequence, and some regexes assume prior replacements. Tests in tests/test_perturb.py verify the output and that build_haystack works with the perturbed variant.
# Experiment and Judge
The classic NIAH experiment (src/experiments/classic.py) builds a two-message prompt: system (“Answer using only the provided context”) and user (“Context: … Question: …”). Temperature is 0. The judge (src/evaluation/judge.py) uses GPT-5.4 with temperature 0 and a short prompt asking for one of correct, incorrect, or abstained. It accepts semantically equivalent answers (rephrasing, case differences).
# Output and Metrics
Results are written incrementally to JSON during the run. After completion, CSV and an HTML report are generated. The HTML report uses Chart.js for bar charts (by model, position, needle pair) and a line chart (accuracy vs context length, log scale). Metrics aggregate correct/total by model, length, position, and needle pair. With trials > 1, accuracy is averaged across trials.
# Implementation details
- Config-driven: Needles, models, context lengths, and positions live in
config.yaml. Easy to add variants and needle pairs. Simplified excerpt:
models:
openai: gpt-5-mini
google: gemini-3.1-flash-lite-preview
judge_model: gpt-5.4
needle_positions: [0, 0.5, 1.0]
context_lengths: [200, 300, 500, 1000, 2000, 4000, 8000, 16000, 32000, 64000, 128000]
needles:
code_perturbed:
pairs:
- id: bender_cache_unguided
question: "What default or fallback value did you notice in the Bender cache backends?"
answer: "719"
needle: |
nibbler_ttl = fry_opts.get("nibbler", fry_opts.get("NIBBLER", 719))
fake_needles: ["60", "3600"]
- Pre-run verification: The runner checks that the needle appears in the haystack for each unique (variant, needle, length, position) before making API calls.
- Async parallelism: Work is split by provider; within each provider, tasks run concurrently with a configurable semaphore.
- Provider protocol: Clean dependency injection for swapping providers or mocking in tests.
- Perturbation isolates parametric knowledge: The perturbed codebase forces retrieval; the script is reproducible via
make perturb-django.
# Limitations and Possible Improvements
These limitations do not affect the main claim but are worth noting for readers who might extend or replicate the setup.
-
Perturbation brittleness: The perturbation script uses ordered string replacement and regexes. Changes to Django cache code may require script updates. A more robust approach would use AST-based renaming or a dedicated refactoring tool.
-
Judge coupling: The judge is hardcoded to OpenAI. Supporting other judge backends would require abstracting the judge similarly to providers.
-
No retries: Transient API failures (429, 5xx) are not retried. The runner logs and marks the result as
error. -
Fake-needle slot mapping: For
needle_position0.0 or 1.0, the needle goes in the first or last slot. For 0.5, it goes in the middle. Other positions (e.g. 0.25, 0.75) still map to the middle slot; the fractional position does not interpolate across slots. -
ENV path:
load_envinconfig.pyresolves.envvia a hardcoded relative path (parent.parent.parent.parent.parent). This works when the project lives underall/03-projects/active/context-rotbut is fragile if the repo is moved.

